A review of Oasis: A Universe in a transformer, and Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion
Overview
World simulators are explorable and interactive systems or models that can mimic real world. Advanced video generation models can function as world simulators, and to achieve it, they should have low latency for input actions, and capable of long sequence generation. Long sequence generation includes capability of long generation itself, preventing error accumulation, and long term context preservation. This post mainly focuses on how related project Oasis: A Universe in a transformer deals with long sequence generation.
Conventional Long Video Generation are inappropriate for World Simulator!
Video Diffusion Models (VDMs)
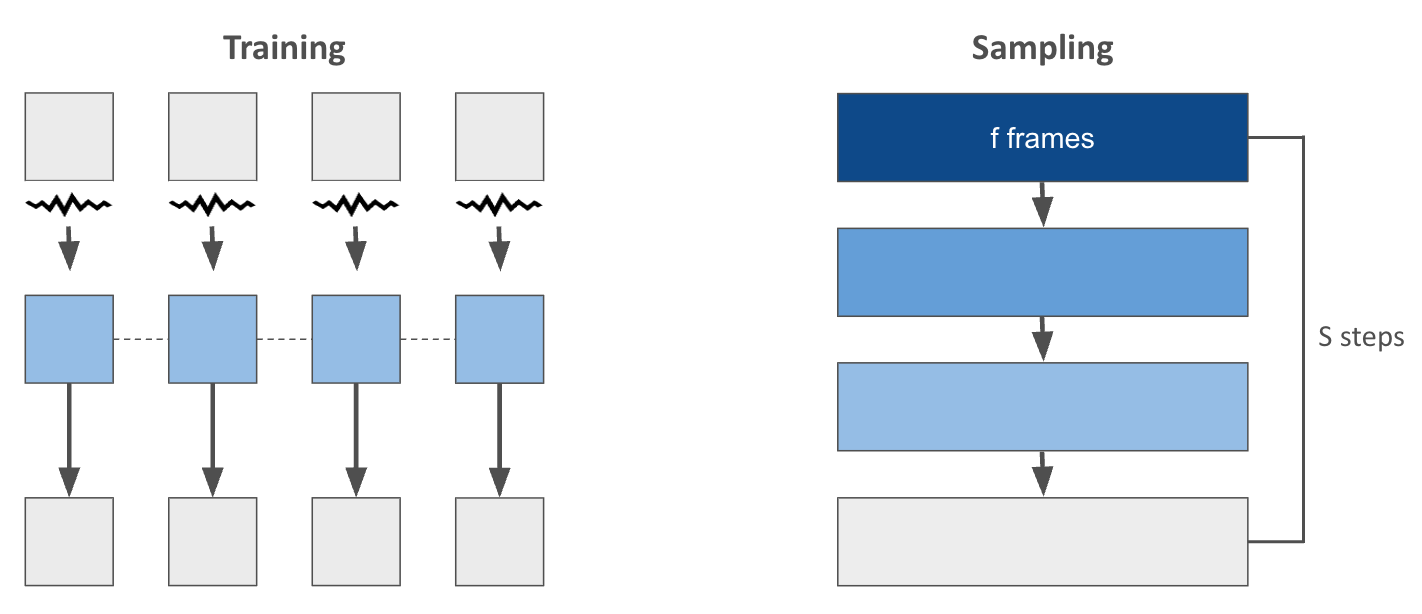
Training and sampling of video diffusion models. Darker tokens has higher noise levels.
Videos are sequential data. However, video diffusion models are trained and inferenced to denoise tokens of same noise levels, interpreting each video clip as a single object. This section reviews approaches to generate long videos using aforementioned VDMs.
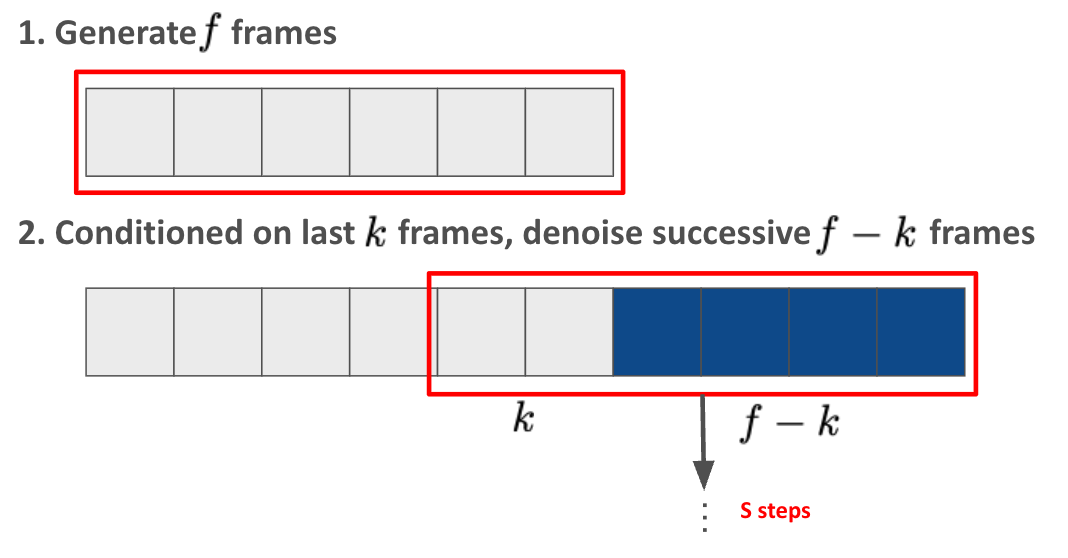
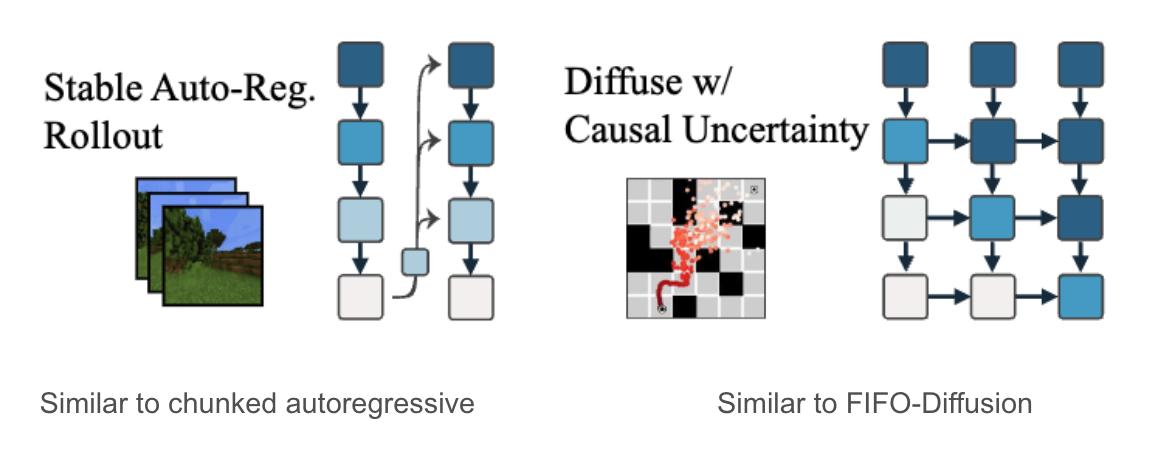
Chunked autoregressive methods
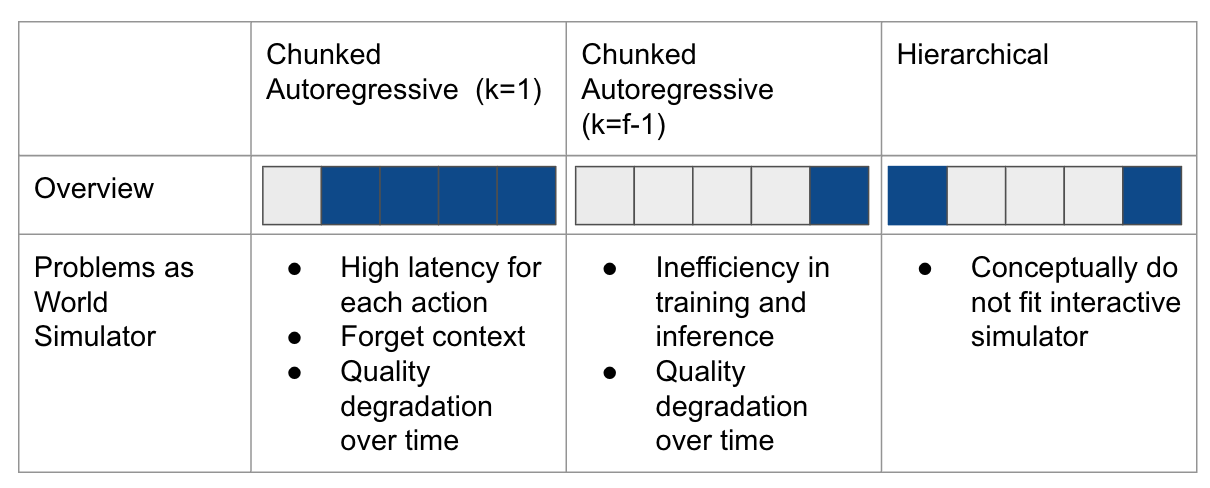
Small \(k\) (e.g. \(k=1\)) results in high latency for each action since \(f-k\) frames are output for each action. Also it tends to lose contexts.
Large \(k\) (e.g. \(k=f-1\)) results in ineifficient training and inference since models learn only \(f-k\) tokens, while models calculate for \(f\) tokens.
Chunked autoregressive methods suffers from quality degradation originated from error accumulation.
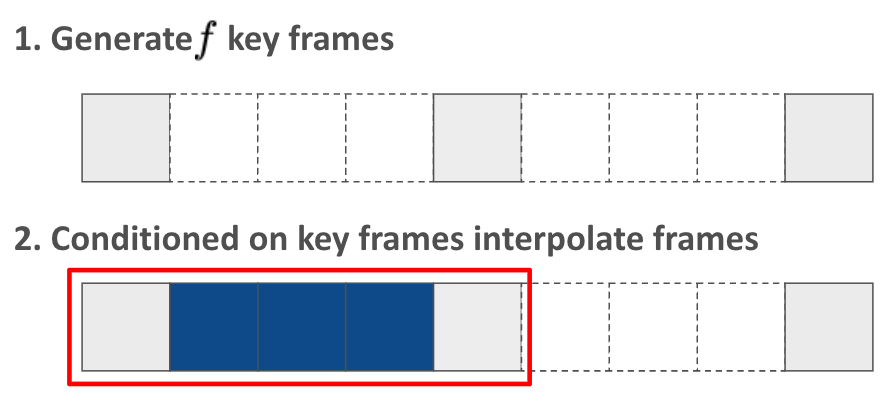
Hierarchical methods (Multi-stage generation)
It does not fit to interactive generation since the end of the video is already determined.
Conventional approaches are not appropriate for wolrd simulator!
Long Sequence Generation in Oasis
Capability of long sequence generation
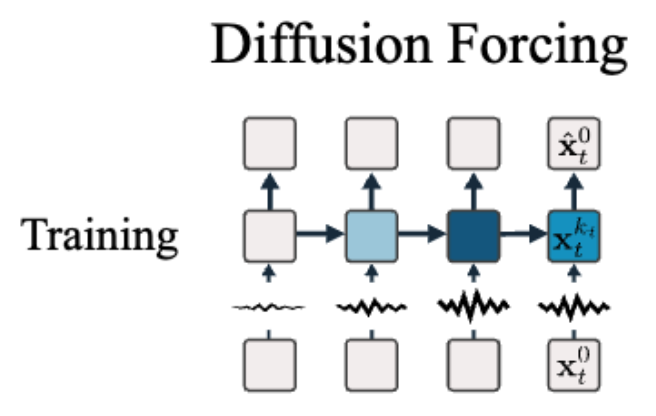
Oasis follows Diffusion Forcing to train models for long video generation. Diffusion Forcing inherits advantages of Teacher Forcing and Diffusion Models: flexible time horizon from Teacher Forcing, guidance at sampling from Diffusion Models.
Diffusion Forcing trains models to denoise tokens with independent noise levels, and sampling noise schedules are carefully chosen depending on the purpose. The training offers cheaper training than next-token prediction in video domain, and the complexity added by independent noise level is not excessive since the complexity is only in temporal dimension.
Training in Diffusion Forcing
Sampling in Diffusion Forcing
Preventing error accumulation
The reason of error accumulation
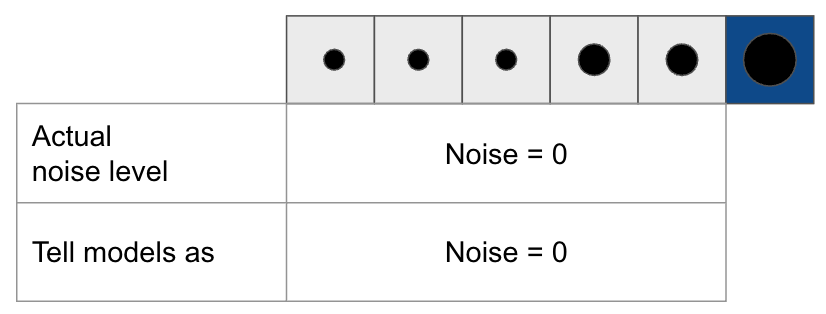
Oasis and Diffusion Forcing hypothesize that the error accumulation stems from the model erroneously treating generated noisy frames as grount truth (GT), despite their inherent inaccuracies. They interpret input noise levels to the models as inversely proportional to the confidence in the corresponding input tokens.
Stable rollout in Diffusion Forcing
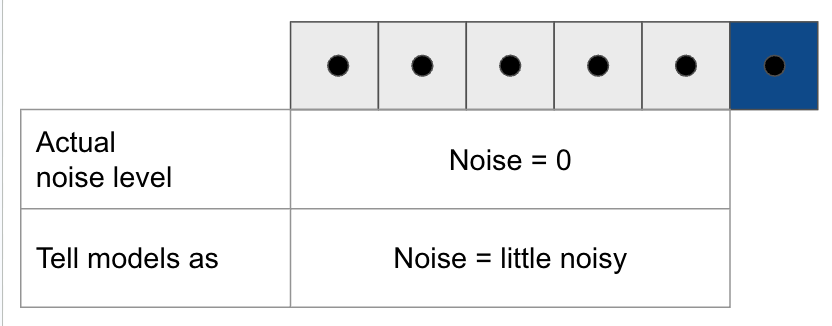
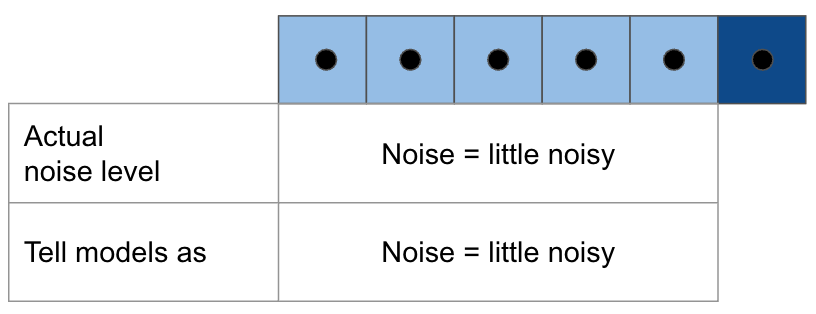
Diffusion Forcing suggests to deceive models that generated clean tokens are little noisy, preventing models from believing generated tokens as GT. However, this approach is out of distribution (OOD) inference, and there is no rule of thumb for “little noisy”.
Stable rollout (Another option)
To avoid OOD, one may suggest add little noise to generated tokens and tell models that the tokens are noisy. However, this approach may dilute details in generated tokens.
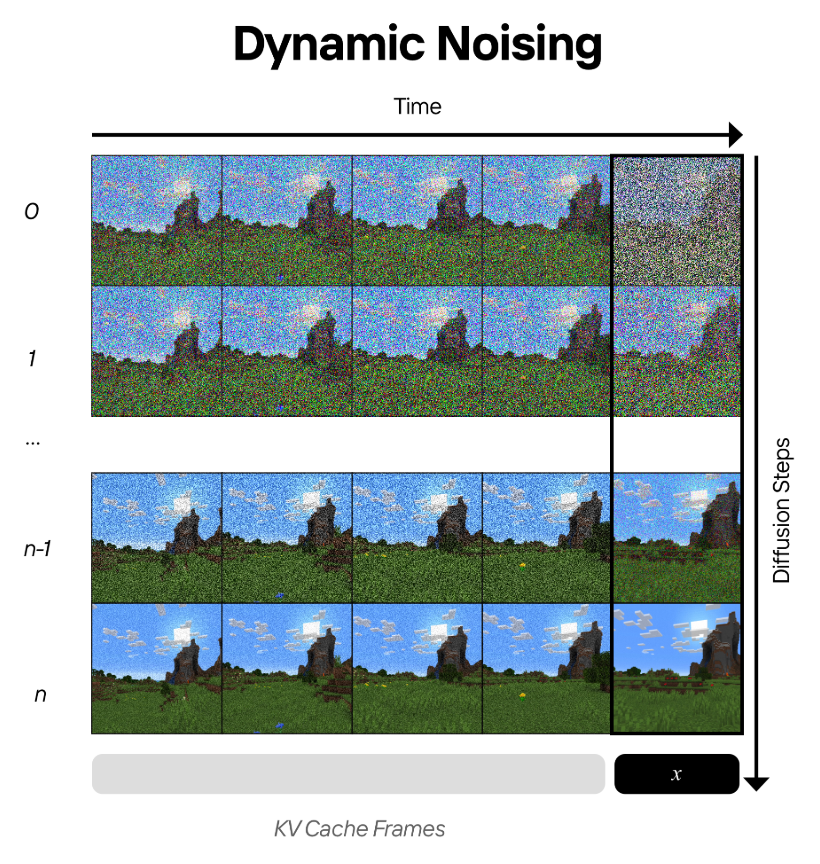
Dynamic Noise Augmentation (DNA)
Oasis suggests Dynamic Noise Augmentation (DNA) to mitigate error accumulation.
For initial denoising steps, conditioning tokens (generated tokens) are moderately noised since models tend to generate low-frequency features during initial steps.
For last denoising steps, noise levels of conditioning tokens gradually decreases.
Long term context preservation
Through above approaches, Oasis can autoregressively generate long videos without much quality degradation. However, models do not have long time horizon memory, leading to inconsistent videos. While there is no innovative breakthrough yet, I believe that video models with long-term memory is an important next step.