Post-Training of Modern LLMs
A review of modern LLM post-training, from RLHF and DPO to reinforcement learning with verifiable rewards, GRPO, and the DeepSeek-R1 pipeline.
Overview
Modern LLMs are usually built in stages. Pre-training gives the model broad next-token prediction capability. Instruction tuning teaches the model to follow user instructions. Post-training then shapes the model’s behavior with preference feedback, reward optimization, or verifiable task rewards.
This post follows two post-training routes. The first is RLHF, where preference data is used through PPO-style reward optimization or direct preference optimization; the examples are InstructGPT and DPO. The second is RLVR, where the reward comes from checkable outcomes rather than a learned preference model; the examples are DeepSeekMath’s GRPO, DeepSeek-R1-Zero, and the final DeepSeek-R1 pipeline.
From Next-token Prediction to RLHF
The limitation of next-token prediction is that it imitates text rather than directly optimizing assistant behavior. A base model can learn fluent language from web-scale data, but helpfulness, truthfulness, and harmlessness are not direct training targets. More importantly, next-token prediction does not provide direct negative feedback on what behavior to avoid.
RLHF adds a preference signal after supervised instruction tuning by increasing the probability of preferred behavior and making dispreferred behavior less likely.
InstructGPT
PPO-based RLHF is the explicit reward-model route. The RL objective is not just “maximize reward.” It also constrains the updated policy to stay close to a reference policy. In InstructGPT, the PPO-ptx objective adds a pretraining loss term to reduce capability regressions:
\[\max_{\phi}\; \mathbb{E}_{(x,y)\sim D_{\pi_\phi^{\mathrm{RL}}}} \left[ r_\theta(x,y)-\beta \log \frac{\pi_\phi^{\mathrm{RL}}(y\mid x)} {\pi^{\mathrm{SFT}}(y\mid x)} \right] + \gamma\, \mathbb{E}_{x\sim D_{\mathrm{pretrain}}} \left[ \log \pi_\phi^{\mathrm{RL}}(x) \right].\]The first term optimizes the reward model while penalizing deviation from the SFT policy. The second term is the ptx loss: it keeps part of the update anchored to pretraining data to reduce broad capability regressions.
Result
The result was strong: PPO and PPO-ptx outperformed SFT and prompted base models on labeler preference evaluations, and the 1.3B PPO-ptx model was preferred over the 175B GPT-3 baseline despite the parameter gap.
Limitation
The limitation is the reward model. It is costly to train, it is not a perfect proxy for human preference, and optimizing against it can create reward hacking or reward-model over-optimization problems.
DPO
DPO is the direct preference-optimization route inside the same preference-based framing. It starts from the same KL-regularized preference view, but removes the explicit reward-model and PPO stages. Its key observation is that the optimal reward can be represented by a policy/reference log-ratio:
\[\hat r_\theta(x,y) = \beta \log \frac{\pi_\theta(y \mid x)} {\pi_{\mathrm{ref}}(y \mid x)}.\]The resulting loss directly compares a preferred answer $y_w$ and a dispreferred answer $y_l$:
\[L_{\mathrm{DPO}}(\pi_\theta;\pi_{\mathrm{ref}}) = -\mathbb{E}_{(x,y_w,y_l)} \left[ \log \sigma\left( \beta \log \frac{\pi_\theta(y_w\mid x)}{\pi_{\mathrm{ref}}(y_w\mid x)} - \beta \log \frac{\pi_\theta(y_l\mid x)}{\pi_{\mathrm{ref}}(y_l\mid x)} \right) \right].\]This is why DPO is sometimes described as RL-free. That phrase is easy to misunderstand. DPO removes the explicit reward model and PPO optimization loop, but it still uses preference pairs, a reference policy, and a KL-regularized objective.
Limitations
The original DPO evidence is also scale-limited. Its strongest reported experiments reach models up to 6B parameters, so the paper should be read as evidence for the tested settings rather than as proof that DPO replaces PPO-based RLHF at frontier scale.
From Preference Rewards to Verifiable Rewards
Preference-based RLHF is useful, but the reward signal is expensive and subjective. Human labelers or reward models must judge completed responses. The learned reward model can also be over-optimized, especially when the policy discovers answers that score well under the reward model without being genuinely useful.
RLVR changes the reward source. In math, code, and some reasoning tasks, the final answer can be checked. A math answer can be compared against the known answer. A program can be run against tests. In these settings, the training loop does not need a learned preference model for every completed answer. This distinction is the bridge from preference alignment to reasoning RL. RLVR is attractive because the reward can be less subjective. The hope is that training on logical, checkable problems can also improve the model’s broader reasoning capability.
| Setting | Reward signal | Natural domain |
|---|---|---|
| RLHF / DPO | Human or model preference | Chat, helpfulness, safety |
| RLVR | Rule-based outcome reward | Math, code, verifiable reasoning |
GRPO and DeepSeekMath
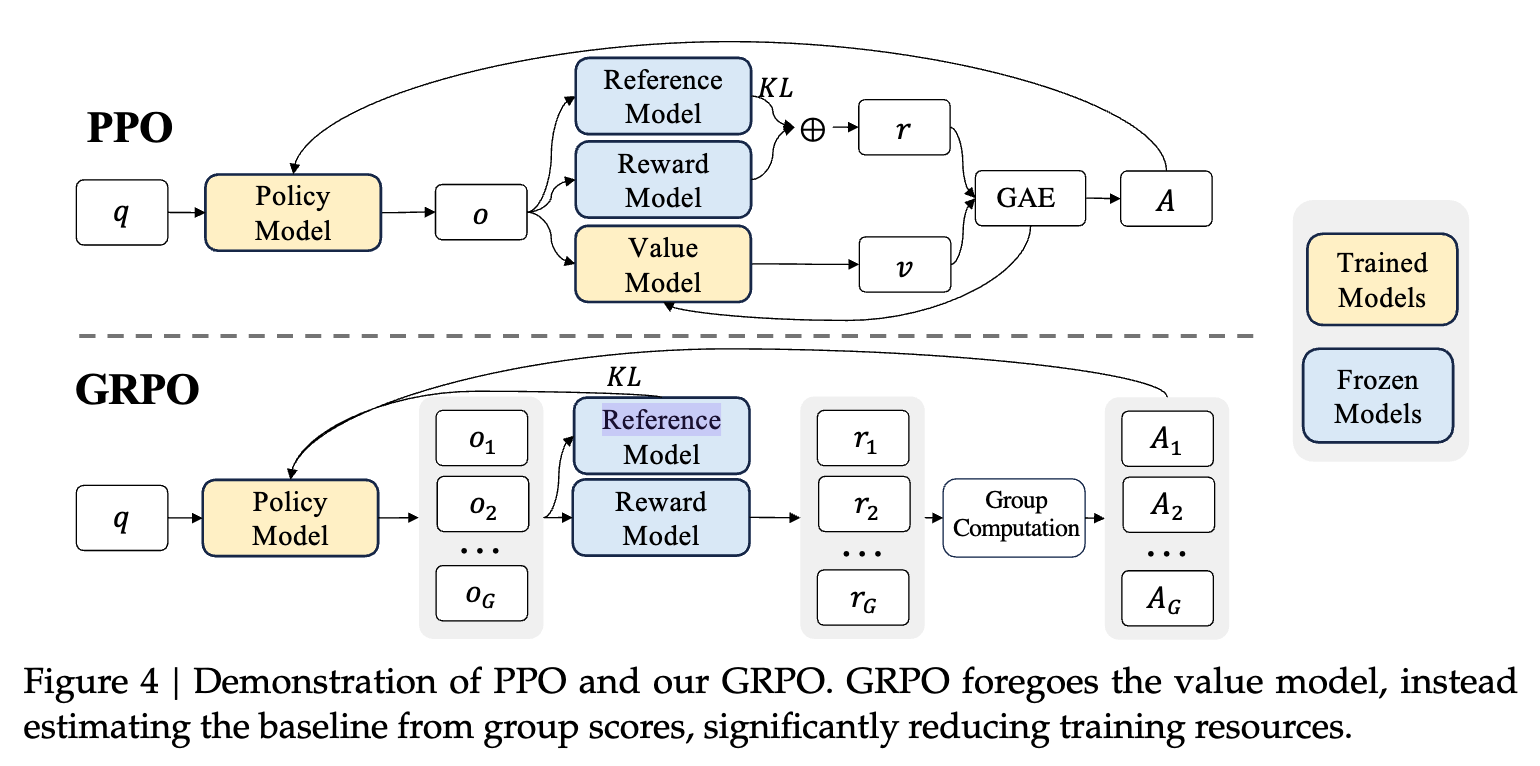
DeepSeekMath introduces Group Relative Policy Optimization, or GRPO, as a PPO-style method for mathematical reasoning. The main engineering problem is the learned value model, or critic. PPO normally uses a value function to estimate advantages. For LLM reasoning, that value model can be another large model, and math rewards often arrive only after a full solution is generated.
GRPO removes the learned critic. For each question, it samples a group of outputs, scores them, normalizes the rewards inside the group, and uses those group-relative values as advantages. The GRPO objective can be remembered as a grouped PPO clipped objective with a reference-policy KL penalty:
The group-relative advantage is:
\[A_i = \frac{ r_i-\operatorname{mean}(\{r_1,r_2,\ldots,r_G\}) }{ \operatorname{std}(\{r_1,r_2,\ldots,r_G\}) }.\]The core move is critic removal, not reward removal. DeepSeekMath-RL still scores sampled outputs and still uses a reference policy for KL regularization. GRPO should therefore be read as a PPO variant, not as a wholly separate reinforcement learning family.
DeepSeek-R1-Zero
R1-Zero is the cleaner RLVR case. It applies RL directly to DeepSeek-V3-Base with verifiable rewards. AIME 2024 is a good example: the final answer is an integer from 0 to 999, so correctness can be checked by exact match. On AIME 2024, the paper reports pass@1 rising from 15.6% to 77.9%, and self-consistency with 16 samples reaching 86.7%. It also reports longer generated reasoning during training.
DeepSeek-R1
R1-Zero shows pure RLVR can induce reasoning, but with usability issues such as CoT readability and language mixing. The final DeepSeek-R1 pipeline turns that idea into a more usable multi-stage training recipe:
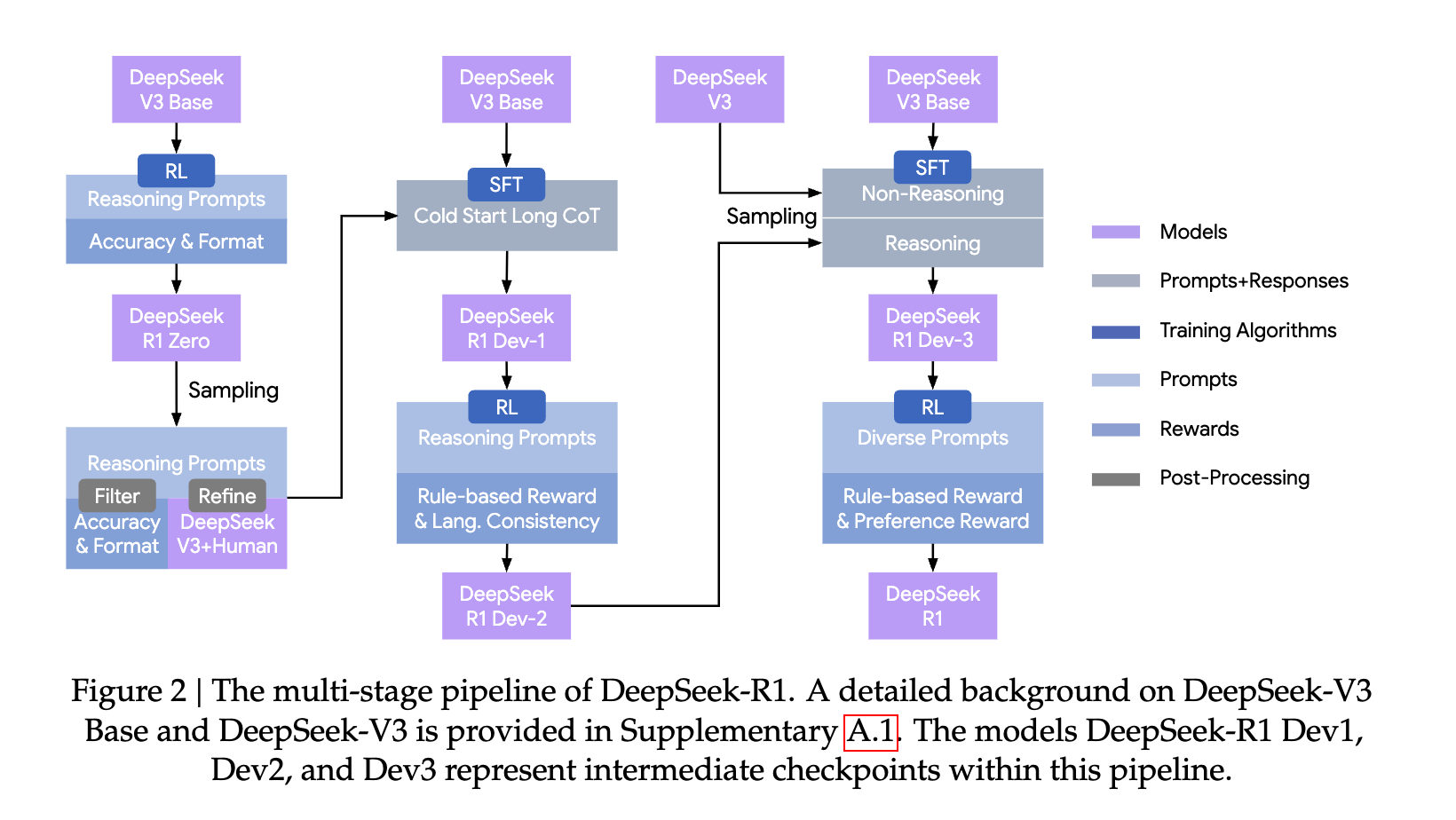
- Cold-start SFT fixes CoT readability before RL.
- First RL improves reasoning while reducing language mixing.
- Second SFT broadens the model beyond math and code reasoning.
- Final RL aligns general assistant behavior with helpfulness and safety.
Limitations of RLVR and GRPO
GRPO normalization bias
GRPO removes the learned critic, but it does not remove all design choices from the objective. Two normalization terms are especially important:
\[\frac{1}{|o_i|}\sum_{t=1}^{|o_i|}L^{\mathrm{PPO}}_{i,t} \qquad A_i = \frac{r_i-\operatorname{mean}(r)} {\operatorname{std}(r)}.\]The first term is length normalization. Because the token-level loss is averaged by output length, a long incorrect output can receive a weaker per-token penalty. If a model expects to be wrong, lengthening the answer can dilute the penalty signal.
The second term is reward standard-deviation normalization. Dividing by $\operatorname{std}(r)$ can overweight questions where the sampled answers have low reward variance. This can happen for very easy questions where most samples are correct, or for very hard questions where most samples are wrong.
Dr. GRPO is motivated by these caveats: it removes both the length normalization and the reward standard-deviation normalization terms.
RLVR outcome-level reward
RLVR usually gives an outcome-level reward. It can check whether the final answer is right, but it does not automatically explain which reasoning step was wrong. It is still a sparse signal for improving the reasoning process itself.
References
- Ernest Ryu, RL for LLMs.
- Ouyang et al., Training language models to follow instructions with human feedback (2022).
- Rafailov et al., Direct Preference Optimization: Your Language Model is Secretly a Reward Model (2023).
- Shao et al., DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (2024).
- Guo et al., DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning (2025).
- Liu et al., Understanding R1-Zero-Like Training: A Critical Perspective (2025).