SFT Memorizes, RL Generalizes
A review of SFT Memorizes, RL Generalizes, focusing on how supervised finetuning and verifier-based reinforcement learning behave under shifted rules and visual inputs.
Overview
This post reviews SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training by Chu et al. The paper asks a simple but important question: when we post-train a foundation model, does the model learn a transferable rule, or does it mainly become better at reproducing the rule distribution seen during training?
The paper finds that verifier-based RL generalizes better than SFT when the evaluation rule changes. In the tested GeneralPoints and V-IRL environments, supervised finetuning improves or fits the training setting but often collapses under shifted rules. PPO-style reinforcement learning with verifier feedback improves out-of-distribution rule and visual performance from the same SFT-initialized checkpoint.
This does not mean that SFT is useless. In the paper’s setup, RL works well after SFT has taught the model a usable answer format; without that SFT initialization, RL does not obtain reliable structured rewards.
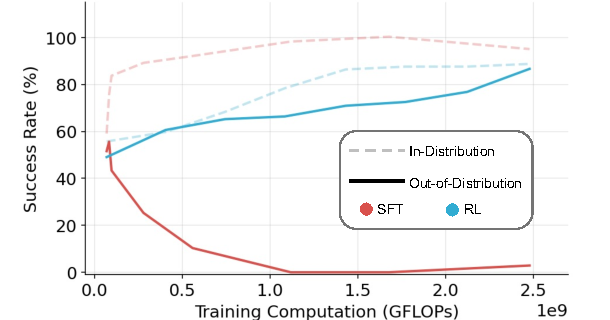 |
|---|
| Figure 1 from Chu et al. illustrates the paper’s core pattern: under an OOD rule shift, RL improves while SFT collapses. |
The Question: Does Post-training Memorize or Generalize?
Post-training is often described as the stage that makes a pretrained model useful. SFT teaches the model to follow instructions and produce the desired answer format. RL then optimizes the model against a reward signal, which can come from human preference models, verifiers, or task-specific outcome checks.
The paper reframes this familiar pipeline as a generalization question. If a model is trained on one rule and then evaluated on a related but different rule, what does each post-training method preserve? A method that really learns the underlying principle should adapt to the new instruction. A method that mainly fits the training distribution may keep applying the old rule even when the prompt states a new one.
Experiment Design: Train on One Rule, Test on Another
This is why the paper compares SFT and RL under shifted rules rather than only in-distribution accuracy. In-distribution improvement alone cannot distinguish rule learning from rule memorization. The interesting test is whether the trained behavior survives when the rule, visual input, or action convention changes.
The paper uses the same high-level experimental pattern across the main settings:
-
Start from the same SFT-initialized checkpoint.
- Scale post-training in two different ways.
- SFT path: supervised examples under the training rule.
- RL path: PPO-style RL with verifier reward and feedback.
- Evaluate after changing the rule or visual condition.
A small but important detail is that verification is iterative. The model can revise its answer after verifier feedback, and one GeneralPoints ablation shows that more verification iterations improve RL’s OOD gains. This supports the idea that RL benefits from learning how to use feedback.
Experiments
Rule Generalization
The rule generalization results are the clearest evidence for the paper’s title. In GeneralPoints, the training rule treats J, Q, and K as 10. The shifted rule evaluates them as 11, 12, and 13. In V-IRL, the training rule uses absolute orientation actions such as north and east. The shifted rule uses relative actions such as left and right.
| Task | RL OOD performance | SFT OOD performance | Metric |
|---|---|---|---|
| GP-L | 11.5% -> 15.0% | 11.5% -> 3.4% | Episode success |
| GP-VL | 11.2% -> 14.2% | 11.2% -> 5.6% | Episode success |
| V-IRL-L | 80.8% -> 91.8% | 80.8% -> 1.3% | Per-step accuracy |
| V-IRL-VL | 35.7% -> 45.0% | 35.7% -> 2.5% | Per-step accuracy |
Under these shifts, RL improves OOD performance from the shared initial checkpoint. SFT moves in the opposite direction. The V-IRL numbers are especially striking. SFT does not merely fail to improve under the shifted action convention. It almost collapses. This supports the paper’s interpretation that SFT can overfit to the training rule or output convention, while verifier-based RL can preserve more rule-following flexibility.
Visual Generalization
The paper also tests whether the RL advantage survives visual shifts. In GP-VL, the shift changes card suit colors. In V-IRL-VL, evaluation moves from New York training routes to the multi-city VLN mini benchmark. This matters because rule following alone does not guarantee robust visual recognition.
| Task | RL OOD change | SFT OOD change | Visual shift |
|---|---|---|---|
| GP-VL | 23.6% -> 41.2% | 23.6% -> 13.7% | Black suits to red suits |
| V-IRL-VL | 16.7% -> 77.8% | 16.7% -> 11.1% | NYC routes to VLN mini benchmark |
The visual results suggest that RL is not only improving final task behavior. In GP-VL, RL improves both recognition accuracy and episode success, while SFT deteriorates both. The authors hypothesize that SFT may locally overfit to frequent reasoning tokens while neglecting recognition tokens, but they leave the exact mechanism unresolved. In V-IRL-VL, verifier-backed revision appears to help the model use visual and instruction information more robustly under a new route distribution.
Why SFT Still Matters
The paper’s conclusion is not “skip SFT.” Its main RL pipeline starts from an SFT-initialized model because the verifier needs structured outputs to assign useful rewards. When the authors apply RL directly to the base Llama-3.2-Vision-11B model on GP-L, the runs fail to improve: the base model often produces long, tangential, or unstructured answers, so the verifier cannot reliably extract task information.
SFT therefore acts as a format teacher. It teaches the model to answer in a way that the verifier can parse, creating the usable initialization window for RL. This also explains why the result does not directly contradict DeepSeek-R1-style claims that strong reasoning behavior may emerge with little or no cold-start SFT in other settings. The requirement depends on the backbone, task, verifier, and output format.
References
- Chu et al., SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training (ICML 2025), arXiv:2501.17161v2.