publications
(*) denotes equal contribution
2025
- ICLREnhanced Diffusion Sampling via Extrapolation with Multiple ODE SolutionsJinyoung Choi, Junoh Kang, and Bohyung HanIn ICLR, 2025
Diffusion probabilistic models (DPMs), while effective in generating high-quality samples, often suffer from high computational costs due to their iterative sampling process. To address this, we propose an enhanced ODE-based sampling method for DPMs inspired by Richardson extrapolation, which reduces numerical error and improves convergence rates. Our method, RX-DPM, leverages multiple ODE solutions at intermediate time steps to extrapolate the denoised prediction in DPMs. This significantly enhances the accuracy of estimations for the final sample while maintaining the number of function evaluations (NFEs). Unlike standard Richardson extrapolation, which assumes uniform discretization of the time grid, we develop a more general formulation tailored to arbitrary time step scheduling, guided by local truncation error derived from a baseline sampling method. The simplicity of our approach facilitates accurate estimation of numerical solutions without significant computational overhead, and allows for seamless and convenient integration into various DPMs and solvers. Additionally, RX-DPM provides explicit error estimates, effectively demonstrating the faster convergence as the leading error term’s order increases. Through a series of experiments, we show that the proposed method improves the quality of generated samples without requiring additional sampling iterations.
- arXivSTR-Match: Matching SpatioTemporal Relevance Score for Training-Free Video EditingJunsung Lee, Junoh Kang, and Bohyung Han2025
Prior text-guided video editing methods often suffer from limited shape transformation, texture or color mismatches between foreground and background, frame inconsistency, and motion distortion. We attribute these issues to the inadequate modeling of spatiotemporal pixel relevances during the editing process. To address this, we propose STR-Match, a training-free video editing algorithm that generates visually appealing and spatiotemporally coherent videos through latent optimization guided by our novel STR score. The STR score captures spatiotemporal pixel relevances across adjacent frames from 2D spatial attention and 1D temporal modules in text-to-video(T2V) diffusion models, without relying on computationally expensive 3D attention. Integrated into a latent optimization framework with a latent mask strategy, STR-Match generates temporally consistent and visually faithful videos, supporting flexible shape transformation while preserving key visual attributes of the source. Extensive experiments demonstrate that STR-Match consistently outperforms previous methods in terms of both visual quality and spatiotemporal consistency. Project page: \hrefhttps://jslee525.github.io/str-matchhttps://jslee525.github.io/str-match
- arXivICM-SR: Image-Conditioned Manifold Regularization for Image Super-ResolutionJunoh Kang*, Donghun Ryou*, and Bohyung Han2025
Real world image super-resolution (Real-ISR) often leverages the powerful generative priors of text-to-image diffusion models by regularizing the output to lie on their learned manifold. However, existing methods often overlook the importance of the regularizing manifold, typically defaulting to a text-conditioned manifold. This approach suffers from two key limitations. Conceptually, it is misaligned with the Real-ISR task, which is to generate high quality (HQ) images directly tied to the low quality (LQ) images. Practically, the teacher model often reconstructs images with color distortions and blurred edges, indicating a flawed generative prior for this task. To correct these flaws and ensure conceptual alignment, a more suitable manifold must incorporate information from the images. While the most straightforward approach is to condition directly on the raw input images, their high information densities make the regularization process numerically unstable. To resolve this, we propose image-conditioned manifold regularization(ICM), a method that regularizes the output towards a manifold conditioned on the sparse yet essential structural information: a combination of colormap and Canny edges. ICM provides a task-aligned and stable regularization signal, thereby avoiding the instability of dense-conditioning and enhancing the final super-resolution quality. Our experiments confirm that the proposed regularization significantly enhances super-resolution performance, particularly in perceptual quality, demonstrating its effectiveness for real-world applications. We will release the source code of our work for reproducibility.
2024
- CVPRObservation-Guided Diffusion Probabilistic ModelsJunoh Kang*, Jinyoung Choi*, Sungik Choi, and Bohyung HanIn CVPR, 2024
We propose a novel diffusion-based image generation method called the observation-guided diffusion probabilistic model (OGDM), which effectively addresses the trade-off between quality control and fast sampling. Our approach reestablishes the training objective by integrating the guidance of the observation process with the Markov chain in a principled way. This is achieved by introducing an additional loss term derived from the observation based on a conditional discriminator on noise level, which employs a Bernoulli distribution indicating whether its input lies on the (noisy) real manifold or not. This strategy allows us to optimize the more accurate negative log-likelihood induced in the inference stage especially when the number of function evaluations is limited. The proposed training scheme is also advantageous even when incorporated only into the fine-tuning process, and it is compatible with various fast inference strategies since our method yields better denoising networks using the exactly the same inference procedure without incurring extra computational cost. We demonstrate the effectiveness of our training algorithm using diverse inference techniques on strong diffusion model baselines. Our implementation is available at https://github.com/Junoh-Kang/OGDM_edm.
- NeurIPSFIFO-Diffusion: Generating Infinite Videos from Text without TrainingIn NuerIPS, 2024
We propose a novel inference technique based on a pretrained diffusion model for text-conditional video generation. Our approach, called FIFO-Diffusion, is conceptually capable of generating infinitely long videos without training. This is achieved by iteratively performing diagonal denoising, which concurrently processes a series of consecutive frames with increasing noise levels in a queue; our method dequeues a fully denoised frame at the head while enqueuing a new random noise frame at the tail. However, diagonal denoising is a double-edged sword as the frames near the tail can take advantage of cleaner ones by forward reference but such a strategy induces the discrepancy between training and inference. Hence, we introduce latent partitioning to reduce the training-inference gap and lookahead denoising to leverage the benefit of forward referencing. We have demonstrated the promising results and effectiveness of the proposed methods on existing textto-video generation baselines. Generated video samples and source codes are available at our project page.
2023
- CVPR
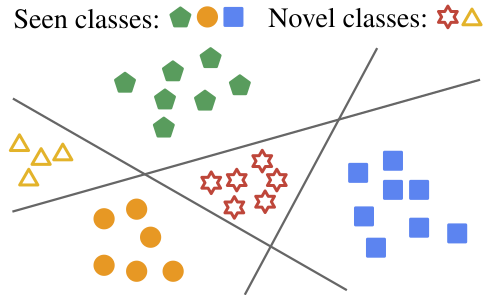 Open-Set Representation Learning Through Combinatorial EmbeddingGeeho Kim, Junoh Kang, and Bohyung HanIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
Open-Set Representation Learning Through Combinatorial EmbeddingGeeho Kim, Junoh Kang, and Bohyung HanIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023Visual recognition tasks are often limited to dealing with a small subset of classes simply because the labels for the remaining classes are unavailable. We are interested in identifying novel concepts in a dataset through representation learning based on both labeled and unlabeled examples, and extending the horizon of recognition to both known and novel classes. To address this challenging task, we propose a combinatorial learning approach, which naturally clusters the examples in unseen classes using the compositional knowledge given by multiple supervised meta-classifiers on heterogeneous label spaces. The representations given by the combinatorial embedding are made more robust by unsupervised pairwise relation learning. The proposed algorithm discovers novel concepts via a joint optimization for enhancing the discrimitiveness of unseen classes as well as learning the representations of known classes generalizable to novel ones. Our extensive experiments demonstrate remarkable performance gains by the proposed approach on public datasets for image retrieval and image categorization with novel class discovery.
